ML and deep learning notes
christopher alexander wrote this book called the Pattern Language. it’s a book filled with 253 patterns to formulate a good space to live in. example: the spot where a building and the street matters immensely for density. more people spilling into streets -> more people naturally want to be in the area -> lively urban spot.


🎯 progress



dec 17th, 2022:
Video: https://course.fast.ai/Lessons/lesson1.html#links
Kaggle Notebook: https://www.kaggle.com/code/chloewchia/is-it-a-bird-creating-a-model-from-your-own-data/edit
Answers to Fastbook 1 Questionnaire: https://forums.fast.ai/t/fastbook-chapter-1-questionnaire-solutions-wiki/65647
Pytorch Image Models: https://timm.fast.ai/
dec 21st, 2022:
Data Augmentation
Training our model
Create our Learner and fine-tune it (show the error rate by epoch)
Confusion matrix is created to see how many differences there are between actual and predicted
Loss = number that will be higher if the model is incorrect
Probability = how confident the model is about its prediction
Model consists of
When we use a model for getting predictions, instead of training, we call it inreference
**Clarifications:
item_tfms are transformations applied to a single data sample x on the CPU
batch_tfms = applied to batched data samples (individual samples that have been collated into mini batch.
dec 24th, 2022:
Tried Kaggle’s ML Course because it seemed more practical code-as-you-go learning style, compared to Fast AI. Imo, it oversimplifies a lot of foundational concepts and leaves you feeling unsatisfied content wise. Will stick with Fast AI for now.
dec 25th, 2022:
dec 26th, 2022
jan 6th, 2022
autoencoders
- learns lower-dimensional representation (encoding) for higher-dimensional data
- trains the network to learn only the most important parts of the image
- unsupervised learning
** artificial neural network
** ground truth
**encoder, decoder
4 Hyperparameters for Training
1. Code size of the bottleneck: how much of the bottleneck data is compressed. Most important hyperparameter
2. Number of layers: depth of the encoder and the decoder. higher depth increases model complexity, whioe lower depth is faster to process
3. Number of nodes per layer: the weights we use per layer. The number of nodes decreases with each subseequent layer in the autoencoder as the input to each of these layers become smaller across the layers.
4. Reconstruction Loss: a measure of how well the data has been reconstructured. the loss function we use to train the autoencoder is highly dependent on the type of input and output we want autoencoder to adapt to. EXAMPLE: image data (most popular loss functions for reconstruction are MSE loss and L1 Loss).
jan 7th, 2022:
Types of autoencoders
1. Undercomplete Autoencoders
- takes in an image and tries to predict the same image as output.
- regulated by the code size of the bottleneck
- reconstruct an image from compressed bottleneck region
- truly unsupervised as they don’t take any label. **the target (remember this is the key word for result) is the same as input
- Main Use Cases: generation of the latent space or the bottleneck, compres
- Better dimensionality reduction alternative compared to PCA (Principal Component Analysis) b/c PCAs can only build linear relationships. While undercomplete autoencoders is nonlinear reduction (called manifold learning).
2. Sparse Autoencoders
- regulated by changing the number of nodes at each hidden layer. how? by penalizing the activation of some neurons in hidden layers
- this allows the network to have nodes in hidden layers dedicated to find specific features in images during training and treating the regularization problem as a problem separate from the latent space problem
Autoencoders led to rabbithole in more
dimensionality regularalization
By regularizing the dimensions of a model, it can be possible to achieve better generalization and improved performance on unseen data.
1. L1 Regularization: adds a penalty term that is proportional to the absolute value of the model weights. this drives the weights towards zero, which effectively removessome dimensions from the model
2. L2 regularization: penalty term that is proportional to the square of the model weights. This also tends to drive the weights towards zero, but not as aggressively as L1 regularization
3. Early stopping: training a model until validation error starts to increase, and then stopping the training
4. PCA: lower dimensional space, linear approach.
dimensions in latent space
- features/variables that are used to describe data points.
- if you have a dataset that contains information about people, the dimensions could be age, weight, height.
- the curse of dimensionality: the number of dimensions increase = increase the amount of data you need to represent relationship between data points. more difficult to make accurate predictions.
latent space
- space in which data points lie
- called latent because not directly observed, but inferred from the relationships between data points
- used for unsupervised learning
unsupervised learning
- goal is to find patterns without any labeled examples
A miscellaneous list of foundational concepts I wanted to make sure I had down (mostly on weights, bias)
**each node consists of something like: input * weight + bias = output
**bias makes up the difference between the function’s output and assigned output
**a low bias suggests that the network makes less of an assumption
** a high bias suggests that the network makes more of an assumption
** activation of a neuron occurs when the sum of the weighted inputs and the bias exceeds a certain threshold
** say you want to classify what an image is. the hidden layers’ job is to learn the specific edges, shapes, patterns of a picture, which are used by the output layer to classify the image. this is called feature learning. the hidden layers are typically responsible for this task.
** Hidden layers in a neural network are layers of neurons that are not directly connected to the input or output layers. They are used to extract features from the input data and pass them on to the output layer. The weights and biases of the neurons in the hidden layers are adjusted during training to optimize the performance of the neural network.
** if the weight is large, that means the corresponding input has a large effect on the output.
transformers
** transformers are made of encoders and decoders.
** encoder receives an input and figures out its features (most important parts)
** decoder uses the encoder’s representation (features) along with other inputs to generate a target sequence
** good explanation of attention in transformers
- to translate “You like this course” to French. You need to focus on the word “You” for the proper translation of “like” because the conjugation depends on the subject. When translating “this” you need to pay attention to “course” because course could be masc/feminine. specific points about transformer architecture 1. input text is converted into a vector via word embedding.
encoder is made up of self attention mechanism and feedforward neural network
**self attention mechanism accepts input encodings from previous encoder and weighs their relevance to each other to generate output encodings.feed-froward neural network processes the output encoding
2. transformers are made of scaled dot-product attention units. attention unit takes in a query, key, and value as input.
3. query = vector representation of word or phrase that model is trying to process. key and value are usually the same, vector representations of the input sentence.
2. attention unit calculates dot product with each of the keys, and applies scaling factor (so the dot product doesn’t get too big)
3. attention unit applies softmax function to scaled dot products, which normalizes them into probability distribution (represents “attention” model gives to each element of the input sequence).
4. attention unit multiplies the values by the attention probabilities and sums them up to produce a weighted sum of values. the exact way that this process knows how much attention to give each word is still cloudy to me, like how exactly does the attention unit and softmax come together to get the probability distribution that is representative of real world language, will look into this deepermulti-head attention
1. one set of weights, query, and value is called an attention head. each layer in a transformer has multiple attention heads. with multiple attn heads, the model can do this for different definitions of “relevance”.
2. many transformer attention heads encode relative relations that are meaningful to humans. some attn heads can attend mostly to the next word. while others mainly attend from verbs to their direct objects.
Encoder have a feed-forward neural network
- during training in the encoder: the attention layers can use all the words in a sentence. the decoder can only pay attention to previous words. otherwise, if it has access to the next word, it wouldn’t be effective training.
Transformers history
**Transformer influential models: GPT (fine tuning NLP tasks), BERT(trained to produce better sentence summaries, GPT-2(improved version of GPT) , BART , GPT-3(bigger version of GPT-2 that is able to perform well without the need for fine-tuning, called zero shot-learning) **zero shot learning example: feed in topics like “politics” “education” and it’ll look for that.
GPT-Like = auto-regressive models
BERT = autoencoding transformer models
BART/T5 = sequence to sequence Transformer models
These have all been trained on large amount sof raw text using self-supervision. humans are not needed to label the data!
fine-tuning is the training done after a model has been pretrained (when the weights are randomly initialized). you first acquire a pretrained language model, then perform additional training with a dataset specific to your task.
https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
❄️ winter break
hellohello. this is a log i kept for picking up ml over winter break. specifically, curious about 1) generating city layouts, open community spaces, quaint downtowns based on a set of parameters like ideal density, people flow, transport and 2) how we can uncover underlying geometric patterns between extremely car-centric places like Houston, Texas vs. micromobility-first locations like Copenhagen.
christopher alexander wrote this book called the Pattern Language. it’s a book filled with 253 patterns to formulate a good space to live in. example: the spot where a building and the street matters immensely for density. more people spilling into streets -> more people naturally want to be in the area -> lively urban spot.


🎯 progress
picked up transformers (multi-head attention, RNNs, BERT), GANs (specifically for generating city layouts, open community spaces, like pix2pix), autoencoders, and read some classical ml papers on nlp for exposure.
timewise: time was split between 1) watching 3blue1brown videos for the core, basic math behind backpropagation/weights. wanted to make sure i understood the math first and foremost. 2) a hugging face project through fast api course (simple classifier), and pytorch from learnpytorch.io.
this piece contains some notes (most are in goodnotes, some screenshots below)


dec 17th, 2022:
Lesson 1 from Fast AI Course: Practical Deep Learning for Coders - Notebook
Video: https://course.fast.ai/Lessons/lesson1.html#linksKaggle Notebook: https://www.kaggle.com/code/chloewchia/is-it-a-bird-creating-a-model-from-your-own-data/edit
Answers to Fastbook 1 Questionnaire: https://forums.fast.ai/t/fastbook-chapter-1-questionnaire-solutions-wiki/65647
Pytorch Image Models: https://timm.fast.ai/
dec 21st, 2022:
Lesson 2 from Fast AI Course: Practical Deep Learning for Coders - Notebook
- Squish or stretch the images = leads to unrealistic shapes
- Crop the images = remove the features that let us perform recognition
- Solution: Randomly select part of the image and crop to just that part
- Epoch - complete pass through all of our images in the dataset
- On each epoch, we randomly select a different part of each image
- Model can learn to focus on and recognize different features in our image
- Reflects how images work in the real world, different photos of the same thing are framed in slightly different ways
- Training the neural network with examples of images where the objects are in slightly different places and different sizes helps it to understand the basic concept
- Replace resize with RandomResizedCrop
Data Augmentation
- Create random variations of our input data
- Appear different through rotation, flipping, perspective warping, brightness changes, and contrast changes
- Use RandomResizedCrop
Training our model
- We have 150 pictures of each sort of bear, which is not a lot of data so we use RandomResizedCrop with an image size of 224 px.
Create our Learner and fine-tune it (show the error rate by epoch)
Confusion matrix is created to see how many differences there are between actual and predicted
Loss = number that will be higher if the model is incorrect
Probability = how confident the model is about its prediction
Model consists of
- Architecture
- Trained parameters
When we use a model for getting predictions, instead of training, we call it inreference
- We get three things: the predicted category, the index of the predicted category, and the probabilities of each category
**Clarifications:
item_tfms are transformations applied to a single data sample x on the CPU
- Resize is a transform
batch_tfms = applied to batched data samples (individual samples that have been collated into mini batch.
- Validation loss is from the validation data
- Subset of training data that is used to tune the model’s hyper parameters.
- But it’s still unseen data!
dec 24th, 2022:
Tried Kaggle’s ML Course because it seemed more practical code-as-you-go learning style, compared to Fast AI. Imo, it oversimplifies a lot of foundational concepts and leaves you feeling unsatisfied content wise. Will stick with Fast AI for now.
dec 25th, 2022:
dec 26th, 2022
Continued Lesson 2 from Fast AI Course: Practical Deep Learning for Coders - Notebook
- Made a Dog Vs. Cat 🐶😽 classifier on Hugging Face, Gradio (interface), and Fast AI’s API. Try it out
- Here are the model’s results on a puppy that looks kinda like a cat
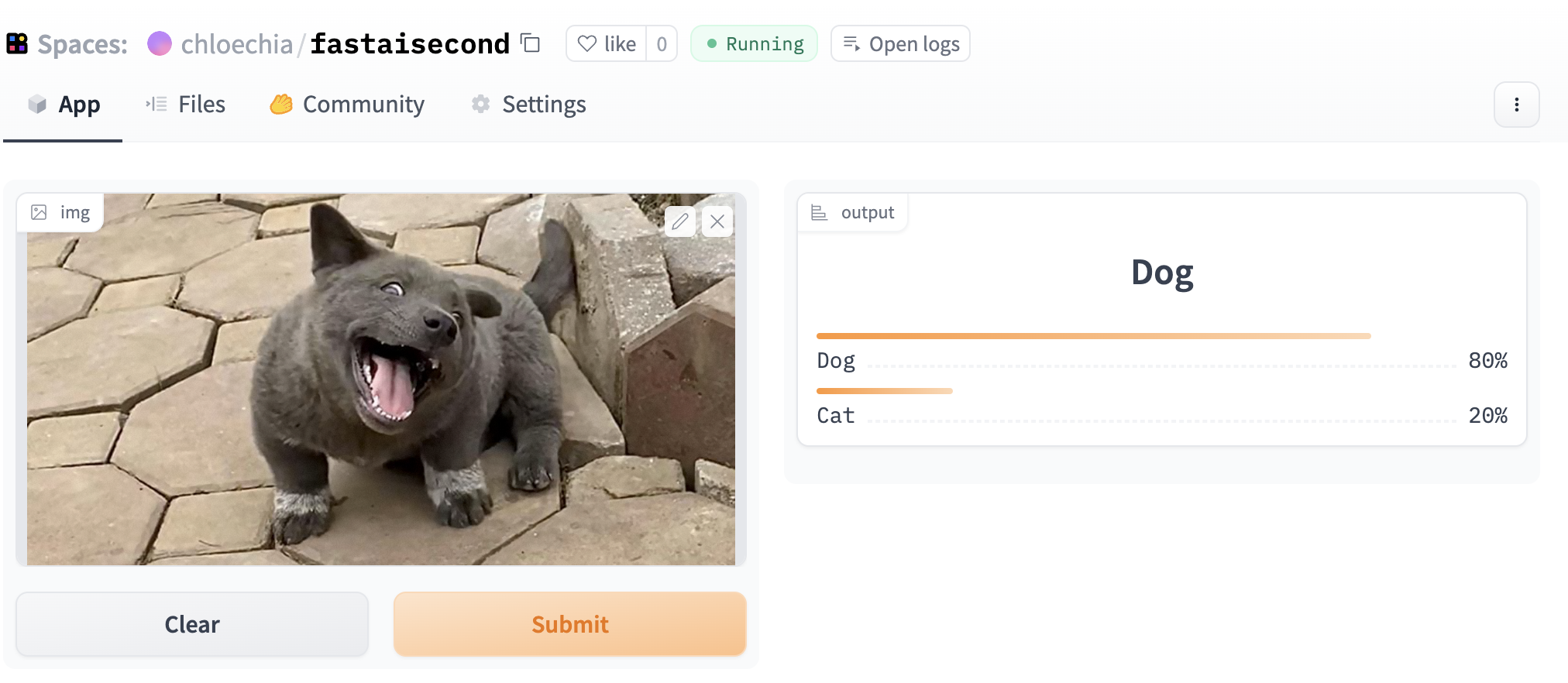
- Watched and completed Lesson 2 of the Fast AI video and the Github textbook. Made sure every line made sense and asked ChatGPT if it didn’t (asked it “from FastAI curriculum...” and it spit out extremely relevant information). A lot of time was spent debugging the Jupyter notebook as some parts were slightly out of date, downloading Github configurations (git lfs) for working with .pkl files, and waiting for the model to train
- Also found this “how to learn ml” piece by a technical staff member at OpenAI, will give it a go!

jan 6th, 2022
autoencoders
- learns lower-dimensional representation (encoding) for higher-dimensional data
- trains the network to learn only the most important parts of the image
- unsupervised learning
** artificial neural network
important terms box
** manifold learning** ground truth
**encoder, decoder
- encoder receives the internal information and turns it into compact internal information
- bottleneck: module that has all the compressed info and is the most important part of the network. restricts the flow of info that passes from the encoder(has lots of info) to the decoder (has very little info), only allowing the most vital information to
- decoder: module that helps decompress and reconstructs the data back into its original form
4 Hyperparameters for Training
1. Code size of the bottleneck: how much of the bottleneck data is compressed. Most important hyperparameter
2. Number of layers: depth of the encoder and the decoder. higher depth increases model complexity, whioe lower depth is faster to process
3. Number of nodes per layer: the weights we use per layer. The number of nodes decreases with each subseequent layer in the autoencoder as the input to each of these layers become smaller across the layers.
4. Reconstruction Loss: a measure of how well the data has been reconstructured. the loss function we use to train the autoencoder is highly dependent on the type of input and output we want autoencoder to adapt to. EXAMPLE: image data (most popular loss functions for reconstruction are MSE loss and L1 Loss).
jan 7th, 2022:
Types of autoencoders
1. Undercomplete Autoencoders
- takes in an image and tries to predict the same image as output.
- regulated by the code size of the bottleneck
- reconstruct an image from compressed bottleneck region
- truly unsupervised as they don’t take any label. **the target (remember this is the key word for result) is the same as input
- Main Use Cases: generation of the latent space or the bottleneck, compres
- Better dimensionality reduction alternative compared to PCA (Principal Component Analysis) b/c PCAs can only build linear relationships. While undercomplete autoencoders is nonlinear reduction (called manifold learning).
2. Sparse Autoencoders
- regulated by changing the number of nodes at each hidden layer. how? by penalizing the activation of some neurons in hidden layers
- this allows the network to have nodes in hidden layers dedicated to find specific features in images during training and treating the regularization problem as a problem separate from the latent space problem
Autoencoders led to rabbithole in more
dimensionality regularalization
By regularizing the dimensions of a model, it can be possible to achieve better generalization and improved performance on unseen data.
1. L1 Regularization: adds a penalty term that is proportional to the absolute value of the model weights. this drives the weights towards zero, which effectively removessome dimensions from the model
2. L2 regularization: penalty term that is proportional to the square of the model weights. This also tends to drive the weights towards zero, but not as aggressively as L1 regularization
3. Early stopping: training a model until validation error starts to increase, and then stopping the training
4. PCA: lower dimensional space, linear approach.
dimensions in latent space
- features/variables that are used to describe data points.
- if you have a dataset that contains information about people, the dimensions could be age, weight, height.
- the curse of dimensionality: the number of dimensions increase = increase the amount of data you need to represent relationship between data points. more difficult to make accurate predictions.
latent space
- space in which data points lie
- called latent because not directly observed, but inferred from the relationships between data points
- used for unsupervised learning
unsupervised learning
- goal is to find patterns without any labeled examples
A miscellaneous list of foundational concepts I wanted to make sure I had down (mostly on weights, bias)
**each node consists of something like: input * weight + bias = output
**bias makes up the difference between the function’s output and assigned output
**a low bias suggests that the network makes less of an assumption
** a high bias suggests that the network makes more of an assumption
** activation of a neuron occurs when the sum of the weighted inputs and the bias exceeds a certain threshold
** say you want to classify what an image is. the hidden layers’ job is to learn the specific edges, shapes, patterns of a picture, which are used by the output layer to classify the image. this is called feature learning. the hidden layers are typically responsible for this task.
** Hidden layers in a neural network are layers of neurons that are not directly connected to the input or output layers. They are used to extract features from the input data and pass them on to the output layer. The weights and biases of the neurons in the hidden layers are adjusted during training to optimize the performance of the neural network.
** if the weight is large, that means the corresponding input has a large effect on the output.
transformers
** transformers are made of encoders and decoders.
** encoder receives an input and figures out its features (most important parts)
** decoder uses the encoder’s representation (features) along with other inputs to generate a target sequence
** good explanation of attention in transformers
- to translate “You like this course” to French. You need to focus on the word “You” for the proper translation of “like” because the conjugation depends on the subject. When translating “this” you need to pay attention to “course” because course could be masc/feminine. specific points about transformer architecture 1. input text is converted into a vector via word embedding.
encoder is made up of self attention mechanism and feedforward neural network
**self attention mechanism accepts input encodings from previous encoder and weighs their relevance to each other to generate output encodings.feed-froward neural network processes the output encoding
2. transformers are made of scaled dot-product attention units. attention unit takes in a query, key, and value as input.
3. query = vector representation of word or phrase that model is trying to process. key and value are usually the same, vector representations of the input sentence.
2. attention unit calculates dot product with each of the keys, and applies scaling factor (so the dot product doesn’t get too big)
3. attention unit applies softmax function to scaled dot products, which normalizes them into probability distribution (represents “attention” model gives to each element of the input sequence).
4. attention unit multiplies the values by the attention probabilities and sums them up to produce a weighted sum of values. the exact way that this process knows how much attention to give each word is still cloudy to me, like how exactly does the attention unit and softmax come together to get the probability distribution that is representative of real world language, will look into this deepermulti-head attention
1. one set of weights, query, and value is called an attention head. each layer in a transformer has multiple attention heads. with multiple attn heads, the model can do this for different definitions of “relevance”.
2. many transformer attention heads encode relative relations that are meaningful to humans. some attn heads can attend mostly to the next word. while others mainly attend from verbs to their direct objects.
Encoder have a feed-forward neural network
- during training in the encoder: the attention layers can use all the words in a sentence. the decoder can only pay attention to previous words. otherwise, if it has access to the next word, it wouldn’t be effective training.
Transformers history
**Transformer influential models: GPT (fine tuning NLP tasks), BERT(trained to produce better sentence summaries, GPT-2(improved version of GPT) , BART , GPT-3(bigger version of GPT-2 that is able to perform well without the need for fine-tuning, called zero shot-learning) **zero shot learning example: feed in topics like “politics” “education” and it’ll look for that.
GPT-Like = auto-regressive models
BERT = autoencoding transformer models
BART/T5 = sequence to sequence Transformer models
These have all been trained on large amount sof raw text using self-supervision. humans are not needed to label the data!
fine-tuning is the training done after a model has been pretrained (when the weights are randomly initialized). you first acquire a pretrained language model, then perform additional training with a dataset specific to your task.
https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)